Project
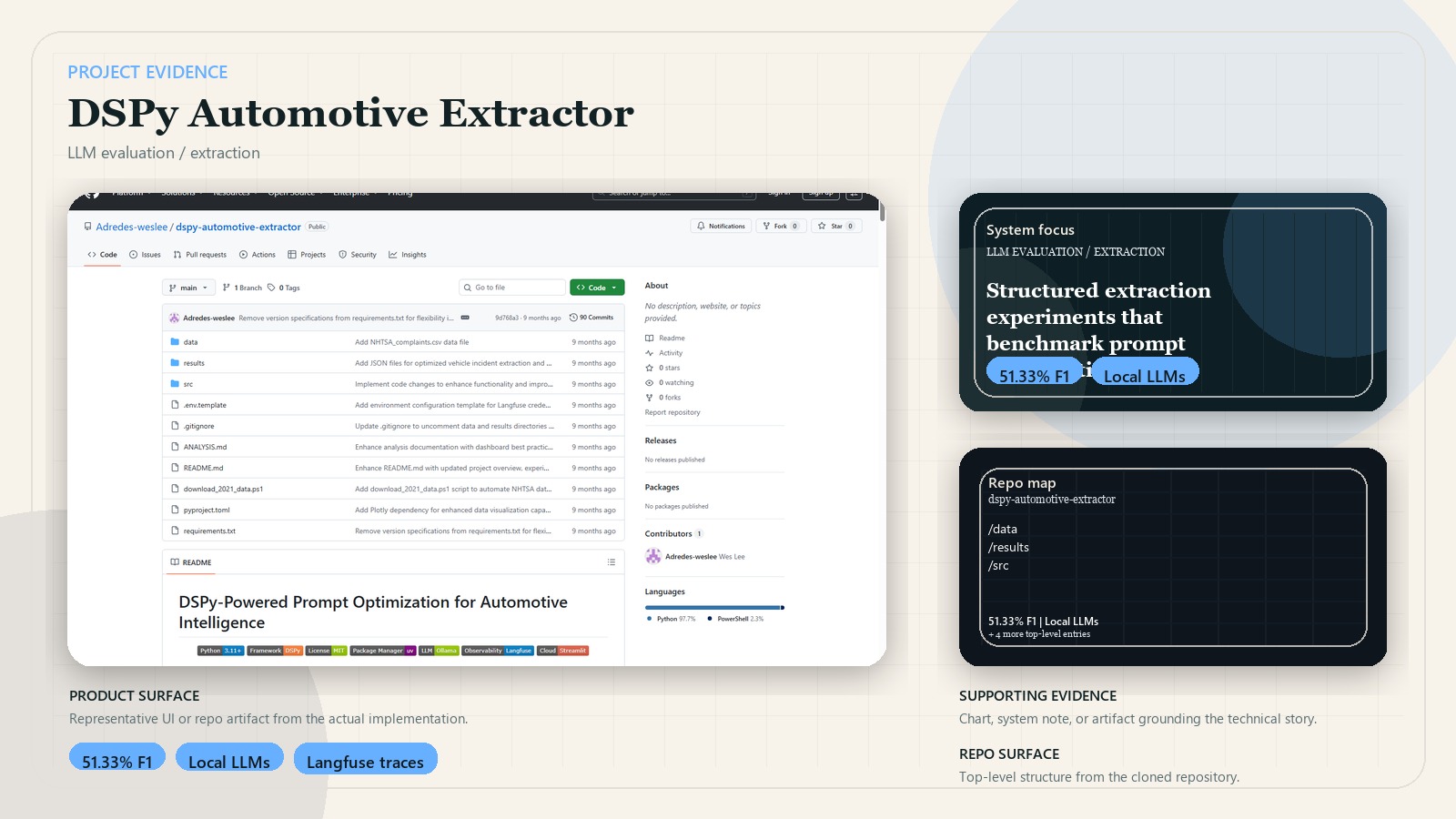
DSPy Automotive Extractor
Structured extraction experiments that show when reasoning fields beat more complex prompt optimization.
Python DSPy Ollama Langfuse Streamlit Pydantic Structured evaluation Local LLMs
Business context
Teams that need structured data from unstructured complaints often rely on manual prompt tweaking, which is slow, inconsistent, and hard to justify in an enterprise setting. This project treats extraction as an optimization problem that can be benchmarked instead of guessed.
Outcome
- Best-performing setup reached 51.33% F1 on structured automotive complaint extraction.
- Phase 1 showed reasoning fields improved every tested strategy.
- Phase 2 showed meta-optimization did not beat the best reasoning-field baseline.
- Delivered both a local-first experimentation workflow and a demo surface for reviewing results.
Key decisions
- Treated prompting as a DSPy compilation problem rather than manual prompt craftsmanship.
- Used local Ollama inference to preserve privacy and avoid external API dependency.
- Split the experiments into reasoning-field tests first, then meta-optimization tests, to isolate the real driver of gains.
- Added Langfuse observability and explicit scoring so results were inspectable and reproducible.
System design
The pipeline loads NHTSA complaint data, defines DSPy signatures and optimization strategies, compiles extraction programs, evaluates them with structured metrics, and surfaces the results through analysis dashboards and interactive testing views.
Stack
- Python, DSPy, Ollama, Langfuse, and Pydantic
- Streamlit for experiment review and interactive extraction testing
- Structured evaluation workflows for prompt optimization benchmarking
