Project
Intelligent Content Analyzer
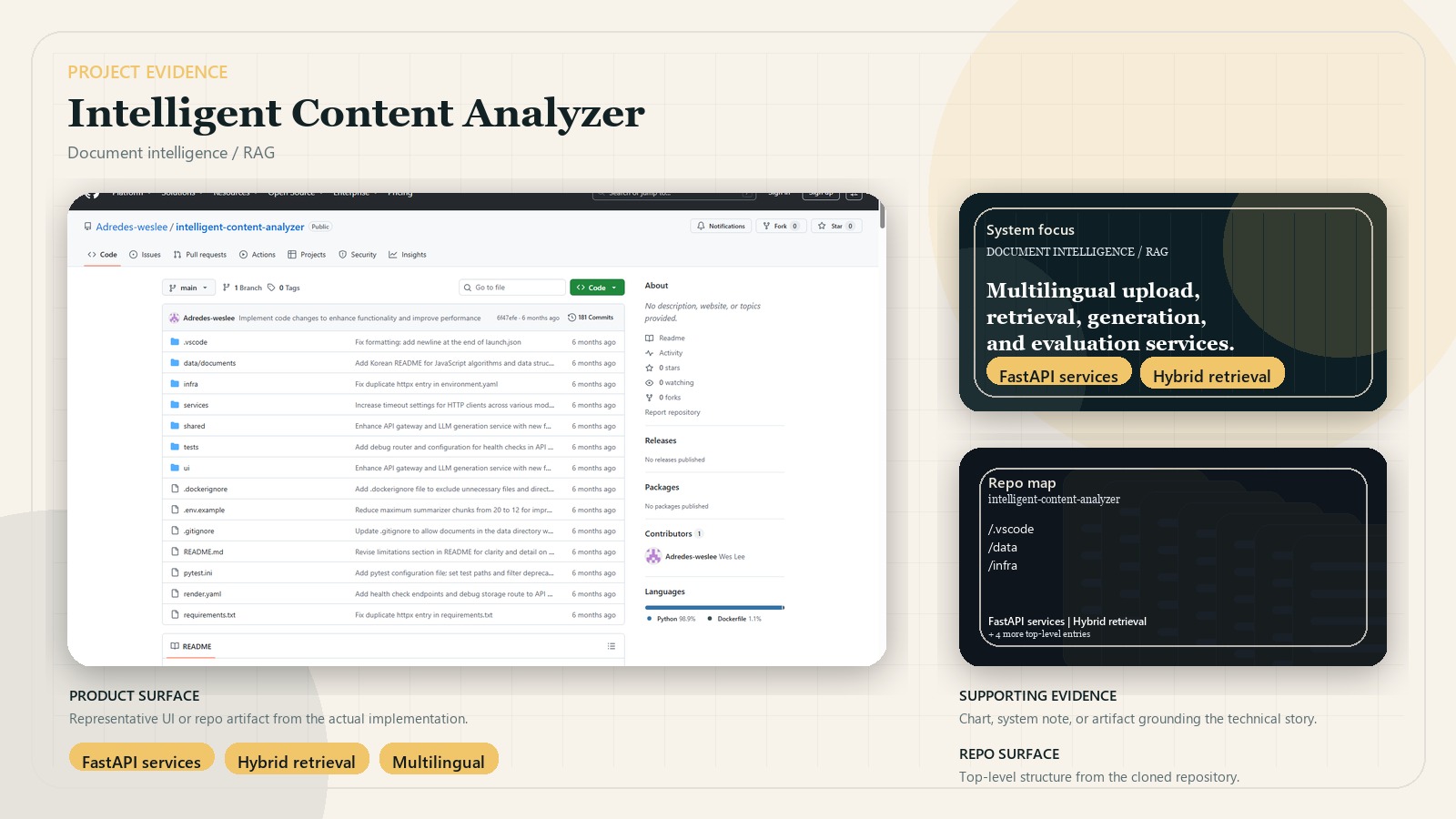
A multilingual document intelligence system built as modular retrieval, generation, and evaluation services.
FastAPI Streamlit FAISS Redis Langfuse Docker Compose Hybrid retrieval Evaluation services
Business context
Students and knowledge workers often need more than a single question-answering endpoint. They need document upload, retrieval, summarization, confidence signals, and multilingual behavior to work together as one product rather than as disconnected experiments.
Outcome
- Provides a public Streamlit UI surface for upload, question answering, and summarization, with the fuller gateway-backed mode available in the repo’s service stack.
- Uses hybrid retrieval, optional reranking, optional Redis cache, and optional Langfuse tracing.
- Supports both local single-process mode and multi-service HTTP mode.
- Preserves the query language in the response path where possible, which makes the system more usable across multilingual inputs.
Key decisions
- Chose a service-oriented architecture instead of one monolithic app.
- Kept a dual deployment model: in-process for simplicity, HTTP microservices for realism and scaling.
- Used hybrid retrieval rather than dense-only search.
- Added evaluation and confidence scoring so answers can be judged, not just generated.
System design
An API gateway orchestrates upload, retrieval, QA, and summary routes. Ingest services parse and chunk documents, retrieval blends sparse and dense search with FAISS, generation handles answer and summary prompts, and evaluation services compute confidence-oriented signals for the UI and API. The public demo exposes the Streamlit UI shell, while the full service-backed deployment path remains the stronger proof of architecture.
Stack
- FastAPI microservices, Streamlit UI shell, and Docker Compose
- FAISS, Redis, Langfuse, and hybrid retrieval components
- Dedicated services for ingestion, retrieval, generation, and evaluation
