Project
Longevity Lab Health Scenario Platform
A public-health risk communication platform with artifact-backed scoring, community-context evidence, model cards, and separate causal-analysis workflows.
FastAPI React TypeScript DuckDB scikit-learn XGBoost Playwright Render Vercel
Business context
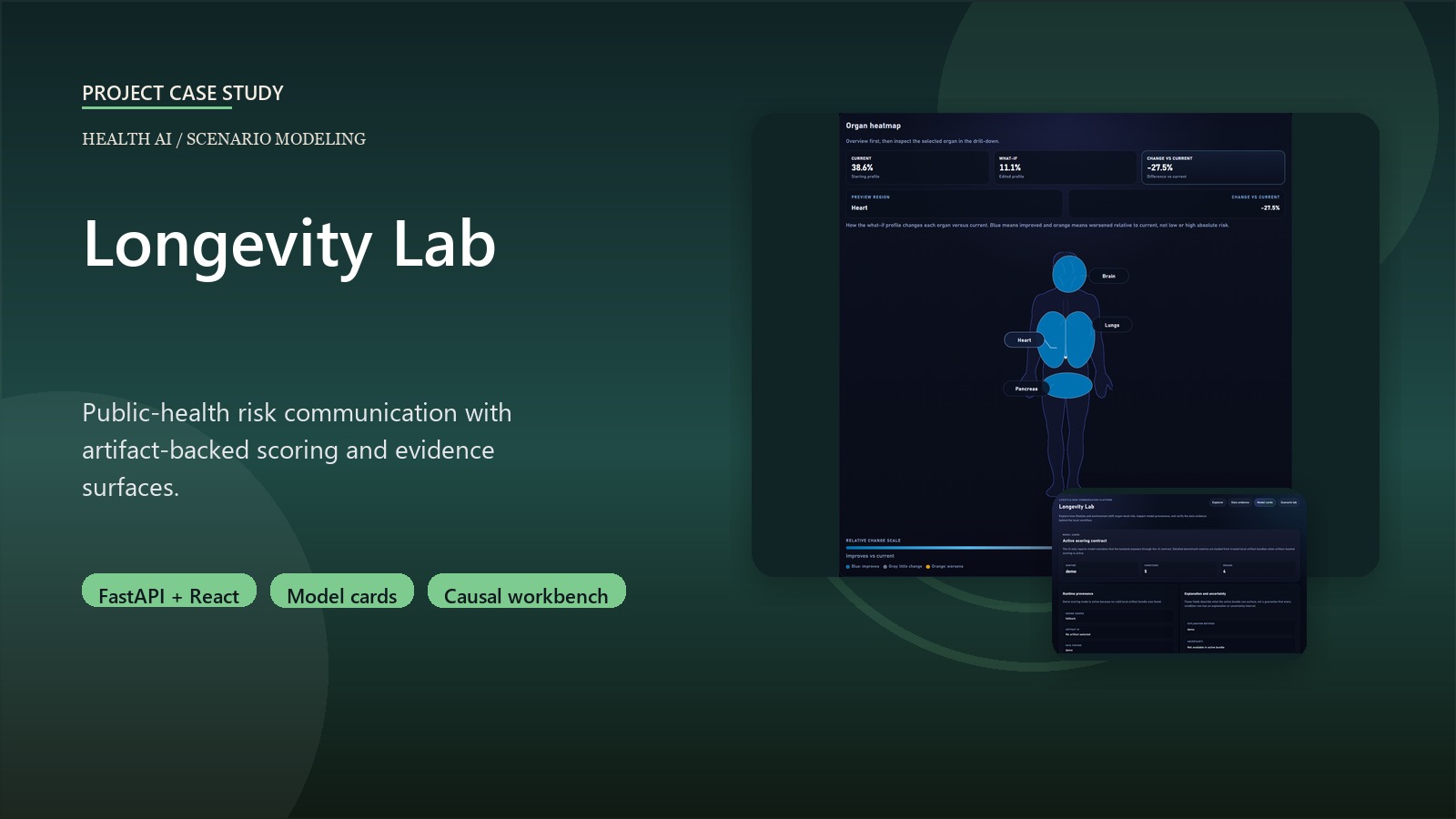
Health-risk interfaces can become misleading when they compress data provenance, predictive scoring, model quality, and causal interpretation into one confident-looking number. Longevity Lab addresses that by treating risk communication as an evidence product: users should see the scenario, the active runtime mode, the data sources, the model-card context, and the caveats around prediction versus causation.
Outcome
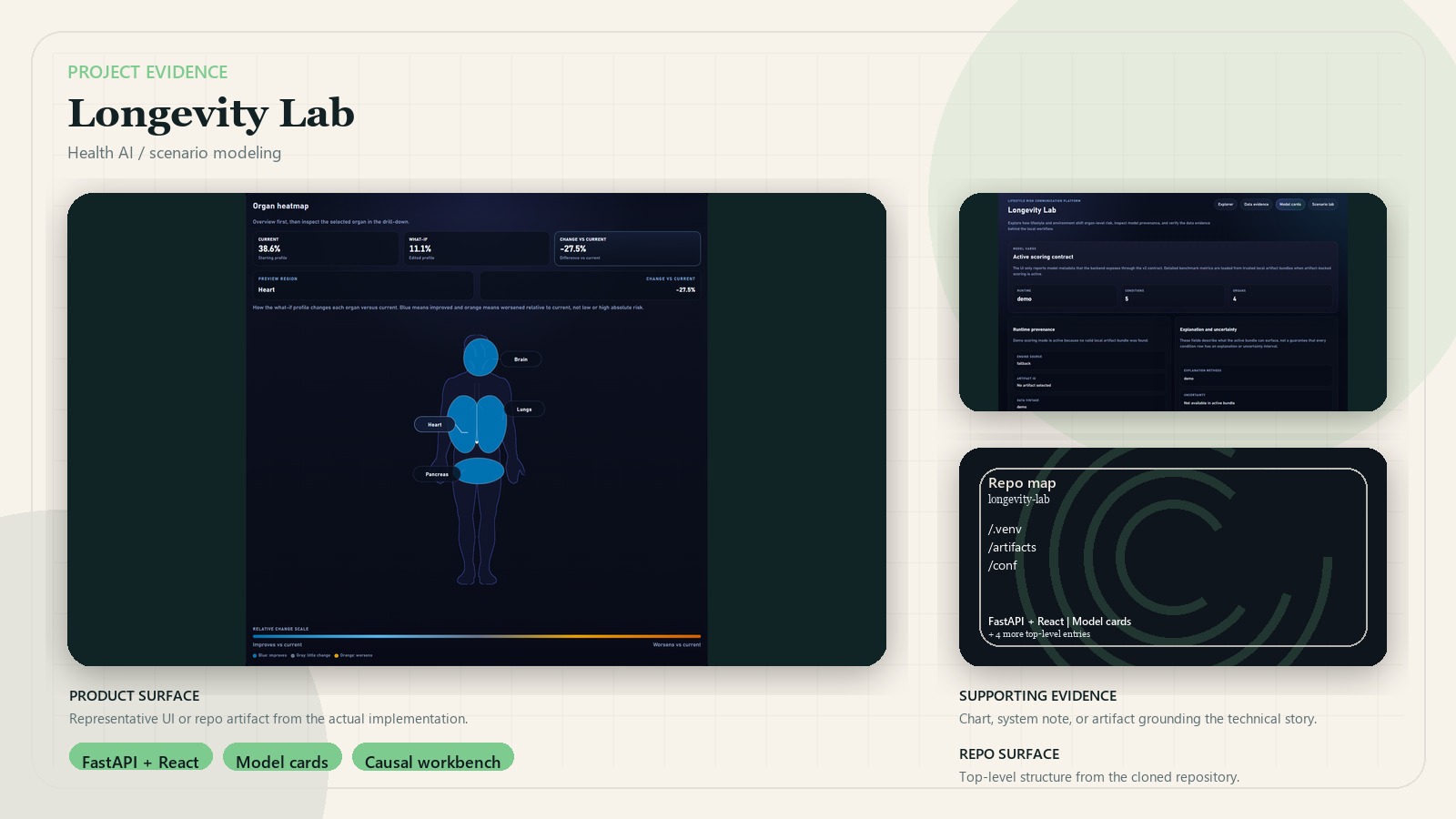
- Built a local-first FastAPI backend and React frontend with Explorer, Data Evidence, Community Context, Model Cards, and Scenario Lab surfaces.
- Published a public Render demo for the React interface; first load can take about a minute while the service wakes and fetches sample data.
- Added public-data pipelines for BRFSS, EPA AirData, ACS, SVI, and CDC PLACES-oriented context, with schema and provenance documentation.
- Added evidence and community-context APIs that separate active scoring inputs from background state-year context, county context, PLACES validation, causal reports, and local-only assets.
- Promoted an artifact-backed production path with verified GitHub Release bundles for calibrated XGBoost scoring, SHAP explanation artifacts, uncertainty metadata, and public evidence panels.
- Implemented artifact-backed scoring paths for eight BRFSS-derived conditions, benchmark harnesses, subgroup metrics, model-card manifests, typed explanations, and calibration intervals.
- Split live slider scoring from selected-condition explanation loading so scenario updates stay responsive while SHAP and rule-path details hydrate only where the user is inspecting.
- Kept causal analysis in a separate workbench so predictive risk scores are not presented as causal or diagnostic output.
Key decisions
- Separated scenario comparison, data evidence, community context, model-card review, scenario summaries, and causal analysis into distinct user-facing surfaces.
- Kept the repo local-first and artifact-aware so large public datasets and trained bundles are not committed into source control.
- Used build-time bundle download and checksum verification so public deployment can run artifact-backed scoring without storing raw datasets in git.
- Used model-card and provenance surfaces to make model behavior inspectable rather than hiding it behind a polished dashboard.
- Used a fast no-explanation compare path for live slider edits, then a lazy explanation endpoint for the selected organ or condition.
- Added deployment guidance for demo/sample-artifact modes without implying that the public surface is a clinical decision system.
System design
Source downloaders and feature builders create public-health tables and derived context features. Training and benchmark scripts produce calibrated model artifacts, metrics, subgroup slices, SHAP explanation metadata, pollutant ablations, uncertainty payloads, and model-card manifests. The FastAPI API exposes health, metadata, scenario, evidence, community, context, pipeline, and model-card contracts, including separate compare and explain paths so score refreshes are not blocked by explanation generation. The React frontend turns those contracts into scenario comparison, data evidence, community context, model-card, and scenario-lab views.
Stack
- FastAPI, Pydantic, DuckDB, pandas, scikit-learn, optional XGBoost, Hydra, and Optuna
- React, Vite, TypeScript, D3 utilities, and Playwright
- Public health data pipelines for BRFSS, EPA AirData, ACS, SVI, and CDC PLACES context
- Render/Vercel deployment profile with
real-20260508-xgboost-shapmodel-bundle verification andpublic-evidence-20260508-community-contextevidence-bundle verification
