Project
Earnings Report Intelligence Platform
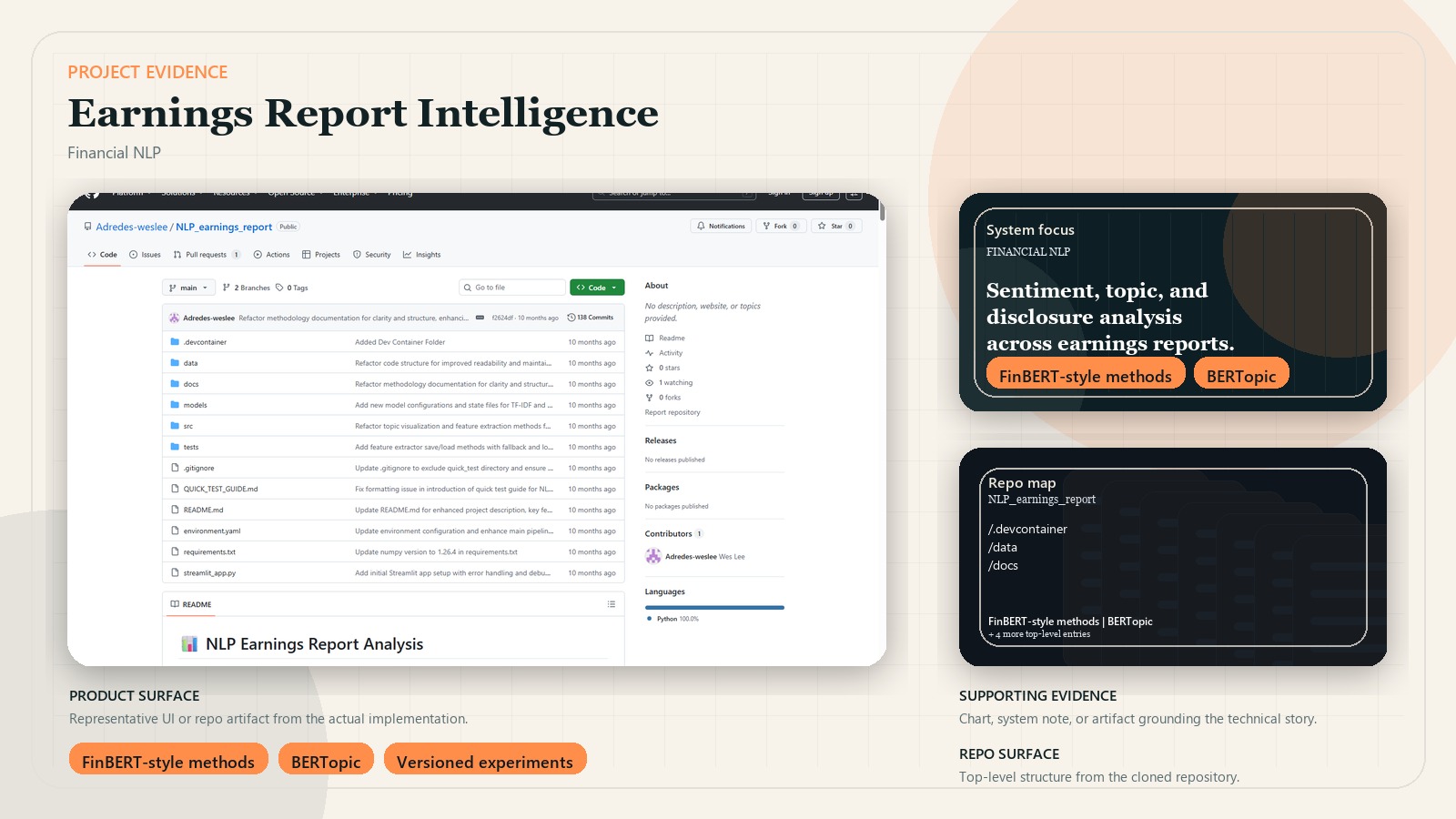
A financial NLP pipeline for sentiment, topic, and disclosure analysis across earnings reports.
Python Streamlit scikit-learn Transformers BERTopic Loughran-McDonald Financial NLP
Business context
Earnings reports are dense, repetitive, and full of signals that are hard to compare consistently across companies. This project was built to turn those disclosures into something analysts can explore through sentiment, topics, extracted metrics, and downstream modeling.
Outcome
- Built an end-to-end workflow from data processing to embeddings, sentiment, topic modeling, feature extraction, and modeling.
- Combined finance-specific lexicons with transformer-based methods instead of relying on generic sentiment tooling.
- Added an interactive dashboard for exploratory analysis and model review, with a lean public demo surface and a heavier local research stack.
- Included data and experiment versioning so the analysis can be reproduced.
Key decisions
- Combined traditional and transformer-based NLP rather than forcing a single method across every task.
- Used finance-domain resources such as Loughran-McDonald and FinBERT-style methods where domain language matters.
- Treated topic modeling as a core analysis layer instead of a side experiment.
- Added versioning so dataset and experiment changes stay traceable.
System design
Reports are collected, cleaned, and transformed into multiple analysis paths for lexicon-based sentiment, transformer inference, topic discovery, feature extraction, and modeling. Those outputs are then surfaced through the dashboard for comparison and exploratory review. The public Streamlit surface stays lightweight, while the verified full local dashboard path uses the repo’s Conda environment to support the heavier NLP stack cleanly.
Stack
- Python, scikit-learn, transformers, BERTopic, and finance-domain lexicons
- Streamlit for interactive analysis, with
environment.yamlas the verified full local run path - Topic modeling, feature extraction, and experiment versioning utilities
