Article
Building ArtifactBench to Evaluate AI-Generated Artifacts
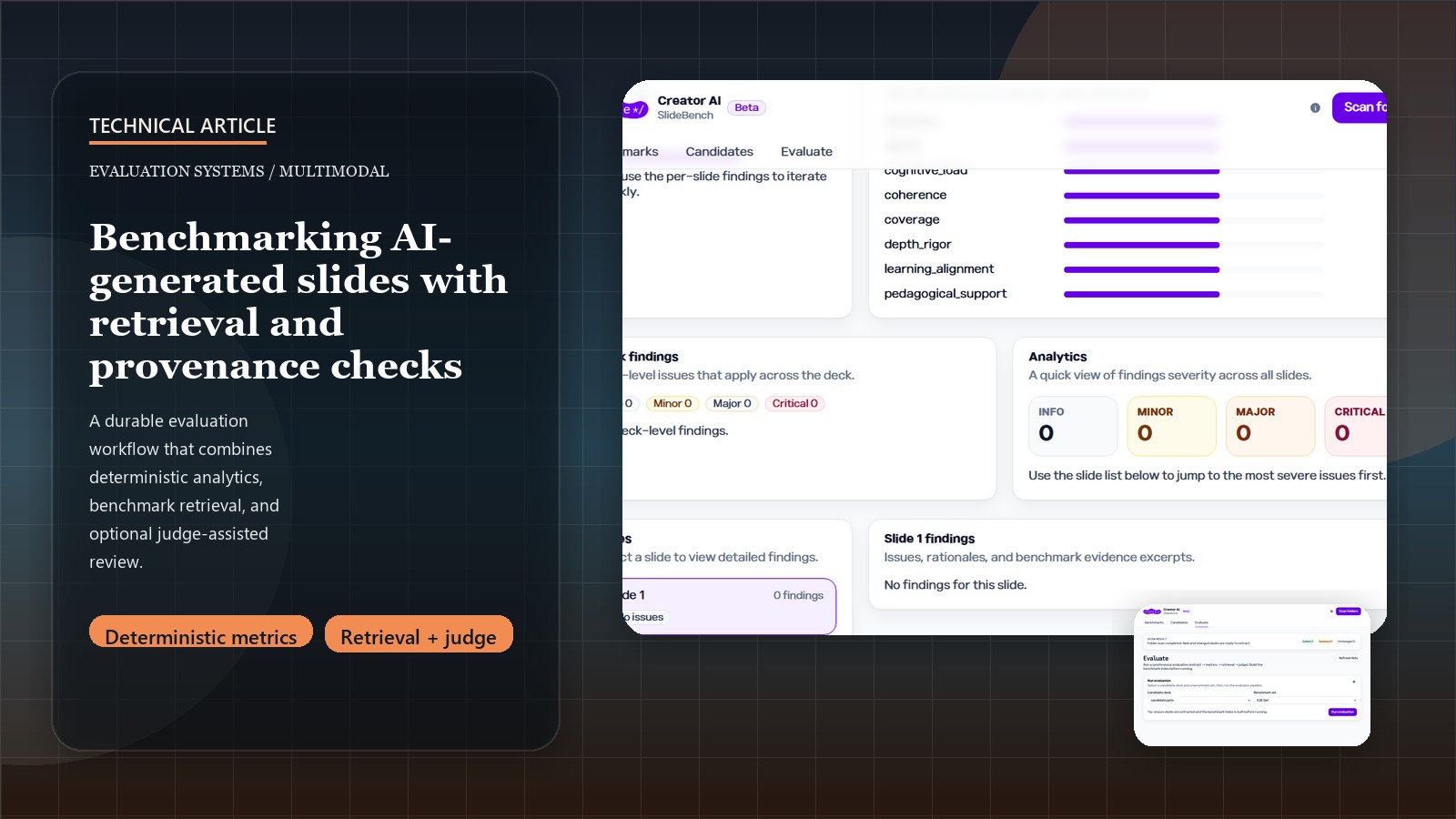
Introduction: generation tools need an evaluation layer of their own
AI-generated artifacts are easy to produce and surprisingly hard to judge well. A deck, curriculum file, project document, PDF, or code bundle can look polished while being repetitive, weakly structured, poorly grounded, or misaligned with the standard a team actually cares about.
That is why ArtifactBench is interesting. It does not treat review as a single judge prompt. It treats evaluation as a product with extraction, deterministic metrics, retrieval over benchmark sets, provenance-aware reporting, and optional model-assisted judgment layered on top.
Related: for the shorter case-study version, see the ArtifactBench project page.
The best choice was combining deterministic analytics with LLM judgment
If a product relies only on deterministic metrics, it misses nuance. If it relies only on an LLM judge, it becomes too soft, too costly, and too hard to reproduce. ArtifactBench takes the more useful middle path.
The evaluation flow separates a few concerns:
- extract structured artifacts from decks, curriculum files, PDFs, and optional project-code bundles
- compute deterministic metrics such as density or redundancy
- retrieve benchmark evidence from curated artifact sets
- invoke an LLM judge only after the structured evidence layer exists
That is a strong design because it means the judge is not asked to invent the whole evaluation frame from scratch. It is asked to reason with evidence that the system already prepared.
Benchmark retrieval turns judging into comparison
One of the better ideas in the repo is the benchmark-set model. Candidate artifacts are not reviewed in a vacuum. They are compared against benchmark corpora, and retrieval is used to surface comparative evidence.
That gives the product a more defensible evaluation posture. It can reason not only about whether an artifact looks acceptable in isolation, but also about how it aligns with known reference material. This is especially important in educational or internal-content workflows where the question is often “how close is this to the standard we already trust?”
It also improves the report UX. Instead of a generic score with thin explanation, the product can connect findings back to benchmark evidence and retrieval output.
Provenance is doing more than compliance work
The provenance guardrails in the repo are a real strength. Candidate evidence and benchmark evidence are tagged separately, and remediation warnings can be attached when provenance is questionable.
That is not just a compliance feature. It improves trust in the evaluation itself. If a reviewer cannot tell whether a finding comes from the candidate deck, a benchmark deck, or a judge synthesis, the report becomes hard to act on. Provenance makes the evaluation more inspectable and the workflow more teachable.
This is the kind of detail that makes an evaluation product feel engineered rather than improvised.
Durable runs and budgets matter in evaluation products too
Evaluation systems have their own operational problems. They can run long, consume provider budget, and fail in the middle of a process. ArtifactBench handles that with durable checkpoints, resumable runs, retries, and optional per-run model budgets.
That is the right product posture. A benchmarking tool should not behave like a toy notebook. It should acknowledge that:
- some evaluations are long-running workflows
- cost needs to be bounded
- operators need visibility into progress and interrupted state
The frontend and backend split reflects that. The UI focuses on benchmark management, progress, and report review, while the backend owns the evaluation state and artifact flow.
The broader scope: this is artifact evaluation, not slide checking
The original name points at slides, but the repo’s actual shape is broader. PPTX files matter, but so do curriculum markdown/JSON, PDFs, and project-code zip inputs. That broader artifact boundary is the stronger portfolio story because the system evaluates generated work products, not just presentation files.
This is also why the provider migration matters. The latest repo drift updates OpenAI defaults and tests around GPT-5.5, but the public claim should not be “new model, better score.” The relevant claim is that provider choices are configurable implementation details under a durable evaluation workflow.
The bigger lesson: AI evaluation deserves product-quality engineering
It is common to talk about generation products and treat evaluation as a helper script beside them. ArtifactBench points the other way. Evaluation can be its own product category with its own workflow design, evidence model, and operational discipline.
That is the key takeaway I would keep from this work:
- deterministic signals and model judgment should reinforce each other
- benchmark retrieval makes reports more defensible
- provenance needs to be visible, not implied
- long-running evaluation deserves durable state and cost controls
In other words, once AI-generated artifacts become common, the systems that evaluate them need to be engineered with the same seriousness as the systems that generate them.
